본 포스팅은 서울대학교 이준석 교수님의 '시각적 이해를 위한 머신러닝 (2023 spring)' 강의를 바탕으로 작성되었습니다.
모든 내용의 출처는 해당 강의에 있습니다.
Courses: http://viplab.snu.ac.kr/viplab/courses/mlvu_2023_1/index.html
Youtube: https://www.youtube.com/watch?v=oqBr_4du-94
Semantic Segmentation

- 기존 분류 문제가 이미지 전체를 대상으로 했다면 semantic segmentation은 픽셀 단위로 분류 수행
First Ideas for Semantic Segmentation

- 단순히 픽셀 하나만 보고 이를 분류하는 것은 어려움
- 그림과 같이 주변 픽셀들도 동시에 보고 타겟 픽셀에 대한 분류 수행
- 이를 단순히 모든 픽셀에 대해 반복
- 단점
- 당연히 매우 비효율적임
- 학습 시에는 몇몇 픽셀을 샘플링하는 방법을 적용해볼 수 있지만, 결국 추론 시에는 모든 픽셀에 대해 수행해야 함
Better Ideas for Semantic Segmentation
Naive Solution

- Fast R-CNN과 같이 이미지를 CNN에 일단 통과시키고 추출된 conv feature로 segmentation 수행
- 그러나 CNN의 경우 출력 크기가 점점 작아지는데, 픽셀 단위의 의미를 보존해야하는 segmentation의 경우 출력 크기는 입력 크기와 동일할 필요가 있음
Fully Convolutional Solution

- 이를 해결하고자, 그림과 같이 입력 크기를 계속 보존하는 CNN을 설계 (다운샘플링 x)
- 그러나 이 또한 역전파 계산 비용이 매우 많이 소모됨
Deconvolution Networks
Main Idea

- 그림과 같이 네트워크 내부에서 다운샘플링과 업샘플링을 수행하여 출력 크기가 동일하도록 함
- 다운샘플링은 Pooling이나 stride를 크게 하는 식으로 가능하지만 업샘플링은 새로운 아이디어 필요
Upsampling

- Nearset Neighbor: 인접 픽셀의 값을 취함
- Bed of Nails: 이외의 값들이 0이 되게
In-Network Upsampling

- Deconvolution Network는 다운샘플링 레이어와 업샘플링 레이어가 쌍을 이룸
- 이러한 사실을 이용하여 그림과 같이 이전 Max Pooling 레이어의 argmax를 기억하고 있다가 Max Unpooling을 할 때 사용
Learnable Upsampling
- 실제로 사용되는 방식
- Downsampling with stride > 1

- 3x3 convolution with stride 2
- 7x7 이미지에 stride가 2인 3x3 컨볼루션을 수행하면 그림과 같음
- 필터가 이미지에 해당하는 정보를 마치 주워 담으면서(picking up) 압축된 새로운 피처를 만듦
- Upsampling with stride > 1

- 3x3 deconvolution with stride 2
- 압축된 이미지의 정보를 필터와 곱하여 마치 도장을 찍듯이(stampling) 펼쳐진 새로운 피처를 만듦
- Examples of deconvolution
- 2D example

- 필터와 곱하여 stampling
- 겹치는 부분은 더해줌
- 1D example


- stride 1 (left) & stride 2 (right)
- 2D example
- 수학적인 특성으로 인하여 Transpose Convolution이라고도 불림

Architecture

U-Net

- Biomedical 분야에서 처음으로 제안된 방식
Encoder

- 일반적인 CNN을 사용하여 spatial pattern을 추출
- 해상도는 절반, 채널 수는 2배로
- 최종적으로는 28 x 28 x 1024
Decoder
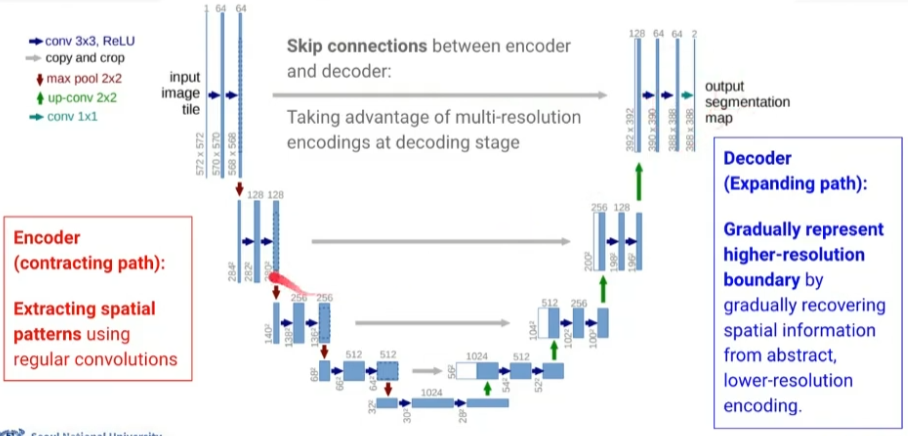
- 그림과 같이 up-convolution (Upsampling)을 수행하면서 크기를 복원함
- up-conv 한 번, conv 두 번 이런 식으로 반복
- 인코더와 반대로 해상도는 2배, 채널 수는 절반
- Skip connections: 디코딩할 때 인코딩 단계의 multi-resoultion을 붙여서 이용
Detailed Ideas
- Different input and output size
- 앞서 U-Net 구조 그림을 다시 보면 입력 크기(572 x 572)와 출력 크기(388 x 388)가 서로 다른 것을 볼 수 있음
- 사실 이는 388 x 388이 얻고자 하는 크기에 해당하고 572 x 572는 패딩을 해준 것
- Mirror extrapolation
- 그림의 노란색 칸이 얻고자 하는 타겟 크기인데, 이를 입력으로 넣을 때는 패딩을 해줘야 함
- 예시의 경우 우측, 하단은 원본 이미지에 그대로 존재하는 부분을 사용하면 되지만 좌측, 상단은 존재하지 않음
- 이를 거울 반사를 시킴으로써 zero-padding을 대체함
- Overlap-tile strategy
- 타겟 크기끼리는 겹치지 않게, 패딩은 겹치게 설정
Loss Fuction
- Pixel-wise softmax

- 최종적으로 얻은 피처 맵과 라벨 간의 픽셀 단위로 cross entropy 계산
- Weighted cross-entropy

- \( d_1, d_2 \)는 각각 해당 픽셀에서 첫 번째로 가까운 경계까지의 거리, 두 번째로 가까운 경계까지의 거리를 의미
- 여기에 (-)를 곱해주고 exp를 취함
- 즉, 비교적 셀 안쪽에 위치한 픽셀은 낮은 가중치를 얻고 경계에 가깝게 위치한 픽셀은 높은 가중치를 얻음
- 경계를 예측하는 게 중요하고 어렵다는 사실을 반영
Applications

Further Reading
- Recent progress in semantic image segmentation
- Large Kernel Matters - Improve Semantic Segmentation by Global Convolutional Network
- See More Than Once - Kernel-Sharing Atrous Convolution for Semantic Segmentation
Instance Segmentation

- object detection + semantic segmentation
- Semantic segmentation은 동일한 클래스의 객체는 구별 불가능
- 이미지 내의 모든 객체를 찾아 분류하고 segmentation까지 수행 (기존 바운딩 박스 대신)
Mask R-CNN
Main Idea

- Faster R-CNN에 mask predicton network를 추가하여 확장
Mask Prediction Network

- Faster R-CNN에서는 나뉘어진 region proposal에 좌표변환을 수행할 때 단순히 반올림하는 식의 양자화가 아루어짐
- Mask R-CNN에서는 인근 좌표로부터 bilinear interpolation을 사용한 RoIAlign을 적용 (더 세밀한 경계 처리 가능)
- ResNet을 사용하여 conv feature 추출
- Detection은 Faster R-CNN과 동일하게 수행
- Mask prediction을 수행할 때는 7x7 피처 맵을 deconvolution을 통해 업샘플링 해주어야 함
- 이어서 pixel-wise cross-entropy 계산
Loss Fuction

Mask Prediction Examples

Segmentation with Transformers
Segmenter
Architecture
- Encoder

- ViT와 동일
- Decoder

- 앞선 인코더의 출력 \( z_L \)에다가 K개의 learnable 클래스 임베딩을 추가함
- N개의 패치 임베딩과 K개의 클래스 임베딩이 Mask Transformer를 거쳐 contextualizing 됨
- 이어서 두 임베딩 간의 내적을 수행하여 N x K 차원으로 만듦
- 이에 대해 업샘플링 적용 (픽셀 단위로 classification 수행하기 위함)
- 최종적으로 각 픽셀은 K개의 클래스에 대한 스코어를 가지고 있고 이에 대해 GT와 pixel-wise softmax 적용하여 loss 계산
Experiments
- Overall performance

- Impact of the patch size

- 패치 크기에 따른 성능과 계산 간의 trade-off 존재
DPT: Dense Prediction Transformer
Main Idea

- 쉽게 말해서, 다양한 패치의 크기를 동시에 반영하고자 하는 시도
- \( {Reassemble}_s \)
- 나누어진 패치들을 s개만큼 다시 묶음 (concatenation)
- 이어서 linear projection을 통해 reshaping
- 즉, 각 패치들은 s배 더 커지게 된 것
- s를 그림과 같이 다양하게 설정 (multi-resolution)
- [CLS] 토큰에 대한 처리가 애매해지는데, 저자들은 ignoring, adding, or MLP로 projection 하는 등의 시도를 함
Results

- semantic segmentation 뿐만 아니라 depth estimation에도 적용 가능
- depth estimation: 픽셀의 원근 정도를 추정
'Computer Vision' 카테고리의 다른 글
| [Computer Vision] Metric Learning (0) | 2024.10.01 |
|---|---|
| [Computer Vision] Object Detection (1) | 2024.09.29 |
| [Computer Vision] Transformers II (4) | 2024.09.27 |
| [Computer Vision] Transformers I (0) | 2024.09.25 |
| [Computer Vision] RNN-based Video Models (3) | 2024.09.24 |