본 포스팅은 서울대학교 이준석 교수님의 '시각적 이해를 위한 머신러닝 (2023 spring)' 강의를 바탕으로 작성되었습니다.
모든 내용의 출처는 해당 강의에 있습니다.
Courses: http://viplab.snu.ac.kr/viplab/courses/mlvu_2023_1/index.html
Youtube: https://www.youtube.com/watch?v=W6EVlzVP0TM
Object Detection
Basics

- 기존 분류 문제는 단순히 이미지를 특정 클래스로 분류하는 것
- 객체 검출은 이미지 내의 객체의 위치와 그 객체가 무엇인지를 추정해야 함
- Class (What)
- Bounding box (Where)
- Confidence
- Dataset
- 데이터셋은 기본적으로 객체의 클래스를 포함하고 객체의 위치는 두 가지 형태로 표현될 수 있음
- \( (x_{min}, y_{min}), (x_{max}, y_{max}) \)

- 중심 좌표 \( (x, y) \)와 높이 \( h \), 너비 \( w \)
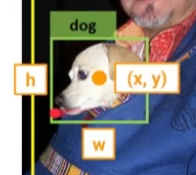
- \( (x_{min}, y_{min}), (x_{max}, y_{max}) \)
- PASCAL VOC, Microsoft COCO
- 데이터셋은 기본적으로 객체의 클래스를 포함하고 객체의 위치는 두 가지 형태로 표현될 수 있음
First Idea for Object Detection
- Single Object Detection

- classification + localization 문제로 볼 수 있음
- Multi Object Detection
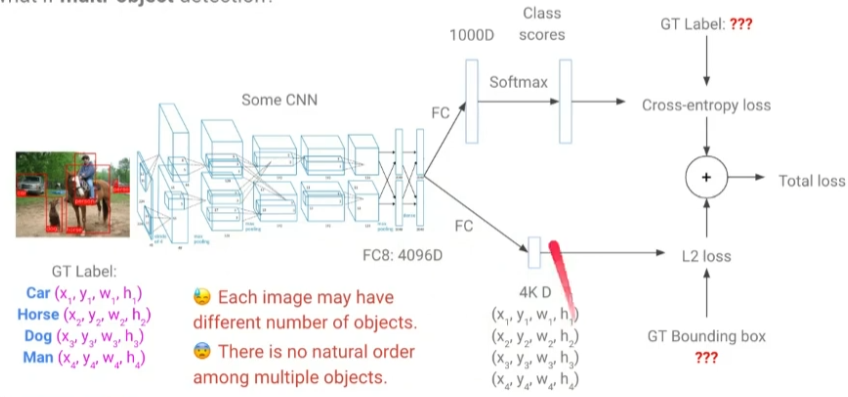
- 각 이미지에 존재하는 객체의 수가 제각각임
- 데이터셋에 지정된 객체 순서대로 모델이 동일하게 찾을 것이라는 보장이 없음
- Brute-force Idea
- 이미지를 여러 장으로 잘라낸 crop된 이미지들을 CNN에 통과시킴
- (None)이라는 클래스를 추가함
- 그러나 이미지를 가능한 모든 경우로 잘라낸다는 것은 매우 많은 계산 비용이 소모됨
Object Detection Approaches
- Proposal-based models
- Two-stage model
- 앞서 brute-force idea와 같이 box를 먼저 만들어내고 detection 수행
- R-CNN, Fast R-CNN, Faster R-CNN, R-FCN, ION, Deformable ConvNets
- Proposal-free models
- proposal 없이 이미지에 대해 바로 detection 수행
- YOLO, SSD, YOLOv2, YOLO9000, DSSD, DETR
Proposal-based Approaches
R-CNN
Main Idea
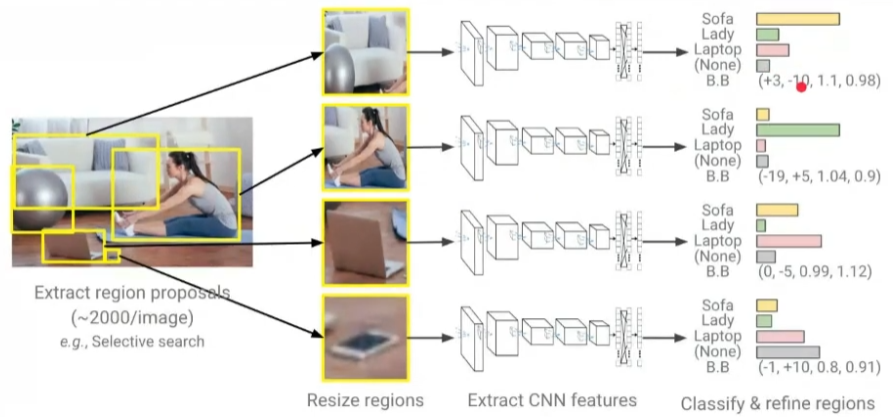
- 'Regions with CNN features'
- Two-stage model: region proposal + recognition
- Stage 1: Region proposal
- Selective search, EdgeBoes, MCG와 같은 고전 모델을 사용하여 bounding box 추출
- 시간이 오래 걸림 (빨라야 이미지 하나 당 0.2초)
- 이미지 하나에 2000개 정도는 추출해야 함
- Stage 2: Object recognition
- 추출된 proposal을 VGG, ResNet과 같은 CNN에 넣고 특징 추출
- 분류 수행
Bounding Box Regression
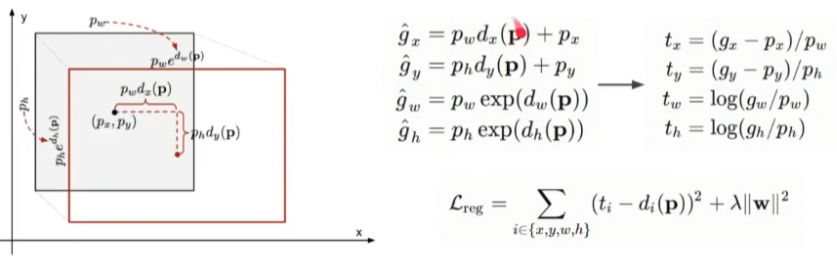
- bounding box의 절대 좌표를 예측하는 것은 어려움 (CNN은 단지 특징만을 추출하기 때문에)
- 따라서 ground truth box 좌표와의 상대적인 차이를 예측하도록 함
- scale-invariant transformation
- \( t_x \): 상하로 얼마나 차이나는지
- \( t_y \): 좌우로 얼마나 차이나는지
- log-scale transformation
- \( t_w \): 폭이 얼마나 차이나는지
- \( t_h \): 높이가 얼마나 차이나는지
- log-scale을 적용하는 이유는 더 미세한 조정을 위해서
Summary
- Why R-CNN?
- 최초 딥러닝 기반의 객체 검출
- brute-force 방식보다 훨씬 적은 계산 비용
- region proposal이 잘 작동한다면 검출도 잘 됨
- Why NOT R-CNN?
- 여전히 높은 계산 비용 (2000 번의 CNN inference)
- region proposal 모델 자체가 오래됨
Fast R-CNN
Main Idea

- R-CNN의 주된 bottleneck을 해결하고자 함
- Stage 1: Region proposal
- R-CNN과 동일하게 사용
- Stage 2: Object recognition
- Project proposal onto features
- 2000개의 proposal에 대해 전부 개별적으로 추출된 feature를 사용하는 것이 아니라, 이미지 전체에 대해 feature를 먼저 추출하고 해당 feature에 대해 proposal을 projection하는 방식
- 즉, region proposal을 conv feature 상에서 얻음
- Region of Interest Pooling (RoI Pooling)
- 추출된 region proposal은 크기가 모두 제각각이기 때문에 이를 7 x 7의 고정된 크기로 나눔
- 이때, 해당되는 각 영역에서 최댓값을 선택하는 max pooling을 적용
- Project proposal onto features
Summary
- Why Fast R-CNN?
- R-CNN보다 정확도가 좋음
- R-CNN보다 8~18 배 정도 학습 시간이 빨라짐
- R-CNN보다 80~213 배 정도 추론 시간이 빨라짐
- 메모리도 훨씬 절약
- Why NOT R-CNN?
- 여전히 off-the-shelf region proposal 모델을 사용 (bottleneck의 주된 원인)
Faster R-CNN
Main Idea
- 기존의 region proposal 모델을 버리고 Region Proposal Network (RPN)을 도입함
- Stage 1: Training the RPN
- conv feature map에 대해 anchor라고 불리는 바운딩 박스의 후보를 준비함
- anchor는 3개의 서로 다른 크기, 3개의 서로 다른 비율로 총 9개
- 앵커가 GT 바운딩 박스랑 충분히 겹치면 positive
- 앵커가 GT 바운딩 박스랑 안 겹치면 negative
- RPN은 이러한 positive, negative를 학습하고, 각 anchor에 대해 positive라면 GT을 따라가도록 학습됨
- conv feature map에 대해 anchor라고 불리는 바운딩 박스의 후보를 준비함
- Stage 2: Fast R-CNN과 동일
Region Proposal Network
- Anchor
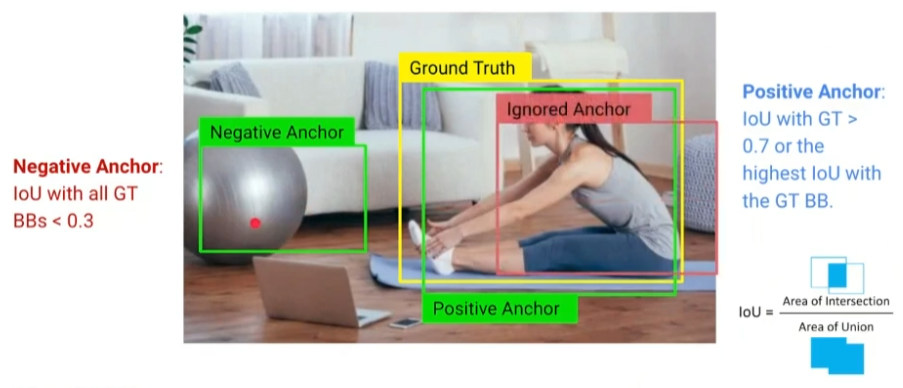
- IoU
- Area of Intersection / Area of Union
- 즉, 교집합 / 합집합
- GT와 anchor 간의 IoU 계산
- IoU > 0.7: positive
- IoU < 0.3: negative
- 0.3 <= IoU <= 0.7: ignored (사용 x)
- IoU
- RPN

- 동일하게 이미지에 대해 conv feature를 추출
- conv feature에 대해 anchor가 마치 컨볼루션 하듯이 움직이면서 다음의 작업을 수행
- positive / negative 판단
- positive인 경우 바운딩 박스의 좌표를 예측하도록 (상하좌우, 폭, 높이)
- 이러한 과정을 3개의 서로 다른 비율(1:2, 1:1, 2:1), 3개의 서로 다른 크기(0.5x, 1x, 2x)로 반복하여 총 9번 수행
- Loss Fuction
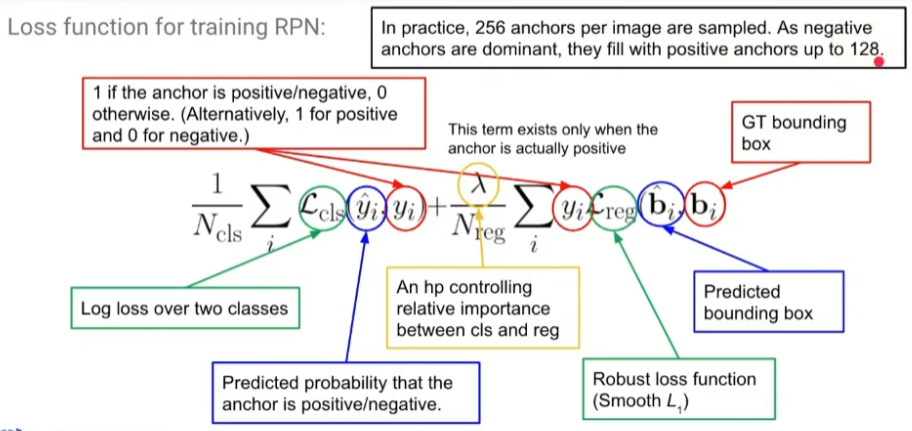
- Training
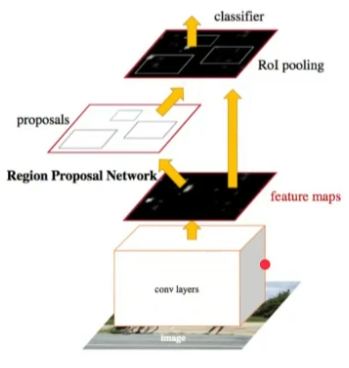
- RPN 학습 → RPN 이용하여 Fast R-CNN의 detection net 학습 → RPN 파인튜닝 → detection net 파인튜닝
- 이와 같이 단계 별로 나눠서 학습 (프레임워크가 지금처럼 발달하지 않아서인 듯함)
Speed
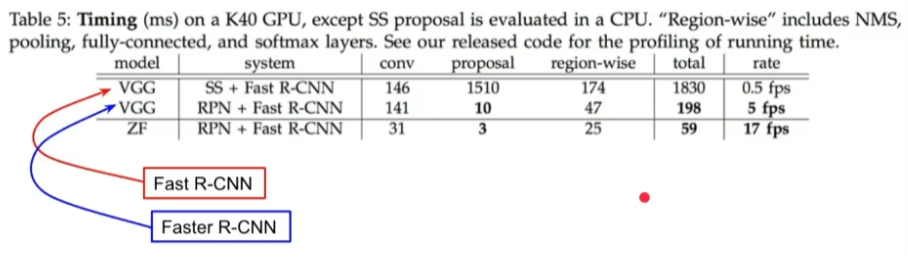
- region proposal 부분을 Fast R-CNN 보다 150배 가량 줄임
Proposal-free Approaches
YOLO: You Only Look Once
Main Idea

- 하나의 신경망으로 바운딩 박스를 예측하고 분류까지 수행하는 one-stage 방식
- detection을 회귀 문제로 접근함
Algorithm

- 입력 이미지는 S x S grid로 나누어짐 (저자들은 S = 7 사용)
- 만약 객체의 중심이 어떤 셀 안에 존재한다면, 해당 셀이 객체를 검출하도록 함
- 각각의 셀은 B개의 바운딩 박스와 confidence 스코어를 예측 (저자들은 B = 2 사용)
- B: 최대 B개의 객체가 셀에 존재할 수 있다는 것을 의미 (객체가 겹칠 수도 있으니까)
- 바운딩 박스에 대한 예측 값: x, y, w, h, confidence
- confidence score = P(Object) x IoU(pred, GT)
- 또한 각 셀은 C개의 클래스 스코어를 예측
- 이에 따라 최종 출력 텐서 크기는 S x S x (5B + C)가 됨
Non-Max Suppression

- 쉽게 말해서, 겹치는 바운딩 박스를 제거하는 과정
- Step 1: confidence 스코어가 가장 높은 바운딩 박스를 취함
- Step 2: 해당 바운딩 박스와 인접한 다른 박스들 간의 IoU를 계산
- Step 3: IoU가 0.5보다 크면 해당 박스를 제거
- Step 4: 다음으로 confidence 스코어가 높은 바운딩 박스로 이동
- Step 5: 이 과정을 반복
Loss Function
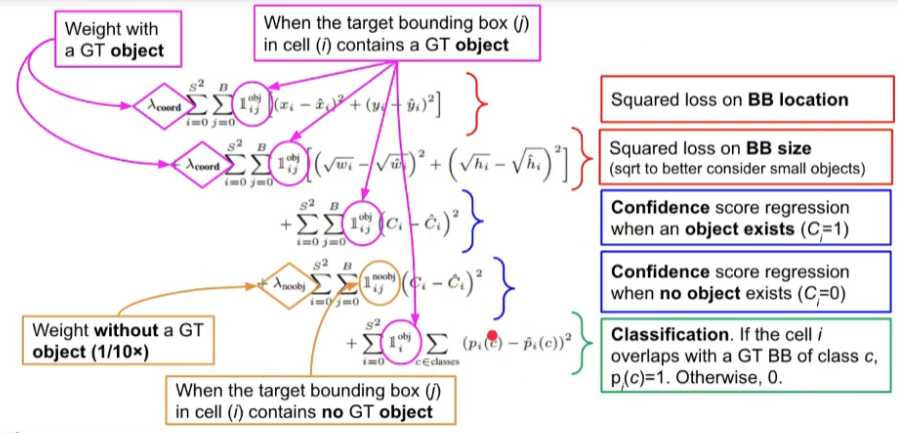
- 1~3행
- target 바운딩 박스에 실제로 GT 객체가 존재할 때
- 바운딩 박스 위치 예측 (1행)
- 바운딩 박스 크기 예측 (2행)
- Confidence 스코어 예측 (3행), GT는 1
- 높은 가중치 적용 (존재하는 객체를 정확히 검출하는 작업이 더 중요)
- 4행
- target 바운딩 박스에 GT 객체가 존재하지 않을 때
- Confidence 스코어 예측, GT는 0
- 낮은 가중치 적용 (1/10 정도)
- 5행
- 각 셀에 대해, GT 바운딩 박스와 겹치면 해당 클래스 스코어가 1이 되게
Results


- Fast / Faster R-CNN보다 성능은 더 낮으나 매우 빠른 속도
- 하위호환은 아니고 두 모델이 서로 다른 부분에서 약점을 보임
SSD: Single Shot MultiBox Detector
Main Idea
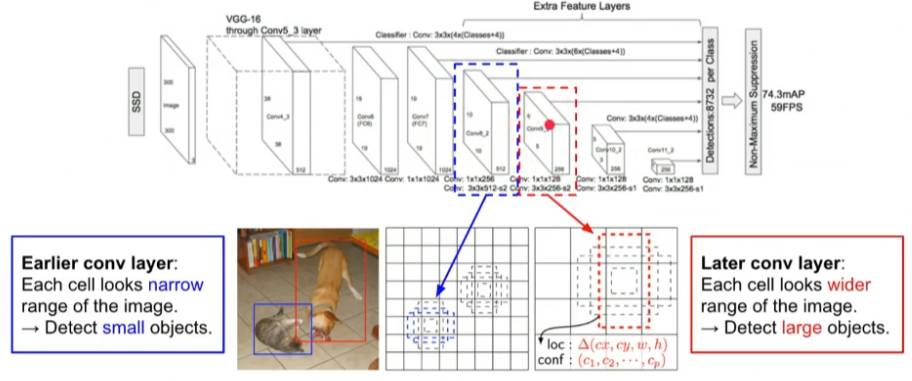
- 객체의 크기가 다양하다는 사실을 반영하여 추가적인 conv layers를 도입함
- 비교적 작은 물체를 검출하기 위해서는 앞단의 conv feature를 사용
- 비교적 큰 물체를 검출하기 위해서는 뒷단의 conv feature를 사용
- 마지막 단에 FC-layer를 삭제하고 Convolutional classifier를 추가함
Loss Function

Results
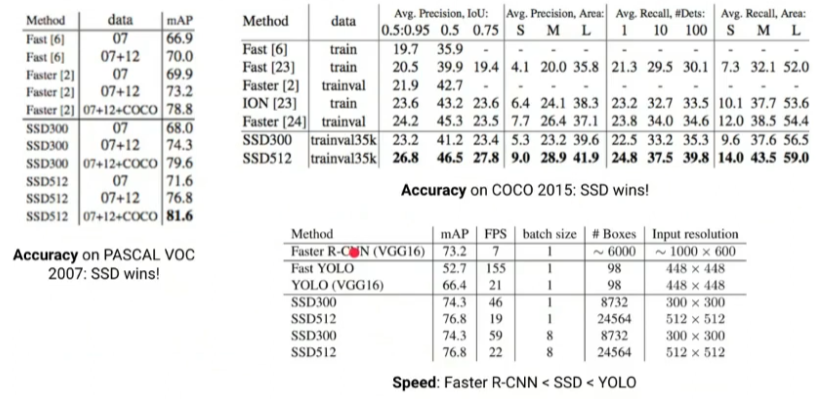
- YOLO보단 느리지만 성능이 더 우수
Transformer-based Approach
DETR: Detection Transformer
Main Idea

- 트랜스포머의 인코더-디코더 구조 적용
- CNN을 통해 conv feature 추출
- positional encoding과 더해서 입력을 구성하고 인코더로 들어감
- 디코더에서 learnable 파라미터로 구성된 object query를 줌
- 이에 따라 디코더는 임베딩을 출력
- FC-layer를 거쳐 각 임베딩은 클래스와 바운딩 박스를 예측
- bipartite matching
- 예측 결과와 GT를 비교할 때, 가능한 모든 조합을 고려하여 GT와 가장 잘 맞는 예측 결과를 loss로서 적용함
- 그 이유는 트랜스포머 디코더 출력의 경우 순서에 대한 정보가 없으니까 (이전 모델들처럼 conv feature에 대해 직접적으로 검출 작업을 수행하는 게 아니기 때문)
- NMS (Non-Max Suppression) 제거
Architecture
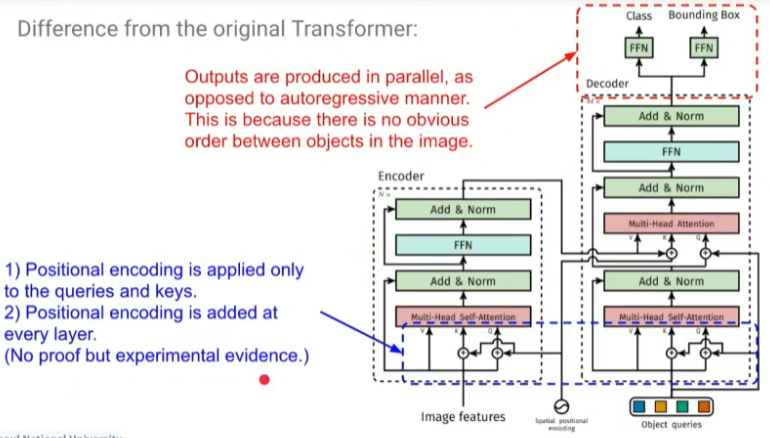
- 클래스와 바운딩 박스를 동시에 출력
- Positional encoding은 Value에는 적용되지 않음
- 각 레이어마다 추가됨
Training
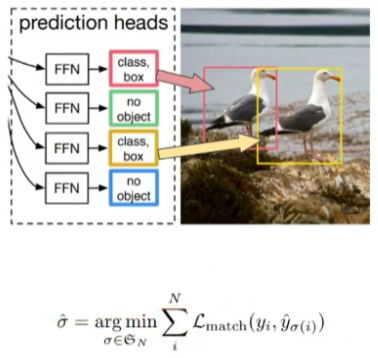
- 예측한 결과나 GT나 정해진 순서가 없음
- 예를 들어 그림과 같이 (bird, none, bird, none)으로 예측했다면 이를 GT와 어떤 식으로 비교하여 loss를 설정해야 할지에 대한 의문이 생김
- 또한 DETR의 경우 고정된 N개를 출력하는데 이는 보통 이미지 내의 객체 수보다 훨씬 많음
- 여기서 bipartite matching을 적용하여 예측 결과와 GT 간의 가능한 모든 조합을 비교해보고 가장 잘 매칭되었을 때를 loss로 적용
- 이에 따라 바운딩 박스들은 독립적으로 학습됨
Results
- 그림의 빨간 점을 쿼리로 주었을 때 어텐션을 잘 수행하는 것을 볼 수 있음

- 어텐션 스코어를 확인한 결과 그림과 같이 객체의 경계 부분에 집중하는 것을 볼 수 있음 (바운딩 박스를 결정하는 데 중요한 역할)

- 작고 많은 객체를 탐지하는 데에 있어서는 약한 모습을 보임

'Computer Vision' 카테고리의 다른 글
| [Computer Vision] Metric Learning (0) | 2024.10.01 |
|---|---|
| [Computer Vision] Segmentation (2) | 2024.09.30 |
| [Computer Vision] Transformers II (4) | 2024.09.27 |
| [Computer Vision] Transformers I (0) | 2024.09.25 |
| [Computer Vision] RNN-based Video Models (3) | 2024.09.24 |