본 포스팅은 서울대학교 이준석 교수님의 '시각적 이해를 위한 머신러닝 (2023 spring)' 강의를 바탕으로 작성되었습니다.
모든 내용의 출처는 해당 강의에 있습니다.
Courses: http://viplab.snu.ac.kr/viplab/courses/mlvu_2023_1/index.html
Youtube: https://www.youtube.com/watch?v=LBqfClEnV2U&list=PL0E_1UqNACXDTwuxUzCl5AeEjXBfWxCwc&index=15
Transformer-based Image Models
ViT: Vision Transformer

Main Idea

- 트랜스포머 모델을 이미지에도 그대로 적용
- Patch embedding
- 이미지를 16x16의 패치들로 분할 (단어의 토큰과 동일한 역할)
- Linear projection을 통해 \( P^2C \)차원의 패치를 D차원으로 변환
- 이러한 패치들의 시퀀스가 입력으로 들어가게 됨
- [CLS] patch
- 기존 트랜스포머와 같이 이미지 전체를 대변하는 [CLS] 패치도 추가됨
- Positional Encoding
- 기존 트랜스포머와 같이 명시적으로 주기 함수를 설정하지 않고 1024 차원의 벡터로 설정하여 패치 임베딩에 붙임
- MSA & MLP
- 패치 시퀀스가 동일하게 MSA, MLP를 거침
- Loss
- [CLS] 패치에 분류기를 달아 계산되고 역전파가 진행됨
Experiments and Discussion
- ResNet152를 넘어서면서 SOTA 달성

- 8개의 TPUv3를 사용하면 300일이 걸림 → 한 번 학습하는데 약 $480,000
- JFT-300M와 같이 매우 큰 데이터셋에서 학습되었을 때만 성능이 잘 나옴

- spatial locality(인접한 픽셀들에 주목)를 사용하는 기존 CNN과 달리 inductive bias에 영향을 받지 않음
- 그림에서 볼 수 있듯이 ViT는 이미지 전체에 주목하여 이미지를 파악함

- 이러한 것들을 순전히 데이터로부터 학습해야 하기 때문에 많은 양의 데이터를 필요로 함
- 그러나 학습이 된다면 spatial locality의 한계를 넘어서면서 CNN 기반 모델들보다 좋은 결과를 얻을 수 있음
Position Embeddings

- 앞서 Position Embedding을 기존 트랜스포머와 같이 명시적으로 설정하지 않았음에도, 그림과 같이 각 패치들의 위치를 잘 파악해낸 것을 확인할 수 있음
DeiT: Data-efficient image Transformers
Main idea

- 매우 많은 시간과 데이터가 소요되는 ViT의 단점을 Distillation을 통해 해결
- 교사 모델로서는 보통 사전 학습된 CNN 모델을 사용 (inductive bias의 장점)
Distillation methods

- 기존 ViT에 distillation token을 추가함 ([CLS] 토큰과 유사한 역할)
- 이 distillation token이 CNN 기반의 교사 모델로부터 정보를 학습함
- Soft-label Distillation

- Classification loss: CLS 토큰과 ground truth 간의 Cross-entropy
- Distillation loss: Distillation 토큰의 logit과 교사 logit 간의 KL 다이버전스를 최소화
- Hard-label Distillation

- Classification loss: CLS 토큰과 ground truth 간의 Cross-entropy
- Distillation loss: Distillation 토큰과 교사 모델의 예측 결과 간의 Cross-entropy (교사 모델의 예측 결과를 true label로서 적용)
- \( Z_s \)가 student logit이라고만 표기되어있는데 CLS 토큰일 수도 있고 Distillation 토큰일 수도 있음
- Observations


- Hard > Soft Distillation
- Distillation embedding > Class embedding
- distillation embedding이 유용한 정보를 더 많이 가지고 있음
Issues with Vanilla ViT Model
- 매우 높은 계산 비용
- inductive bias를 사용하지 않았기 때문에, 대부분의 경우 인접한 패치들로부터 정보를 얻을 수 있음에도 이미지의 모든 패치를 참조해야 함
- 고정된 크기의 패치
- 이미지 상에서 존재할 수 있는 요소들의 다양한 크기를 고려하지 않고 인위적으로 고정된 크기로 잘라냄
- 이에 따라 inductive bias를 다시 적용시킨 두 모델이 비슷한 시기에 제안됨
- Swin Transformer
- Convolutional vision Transformer (CvT)
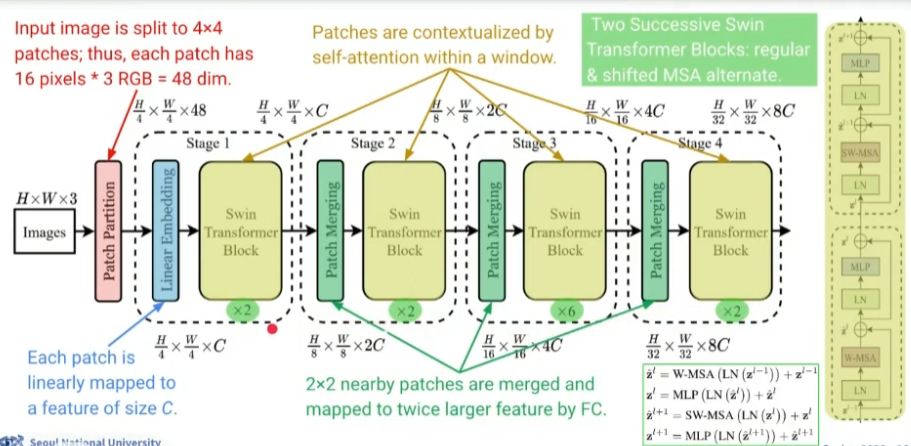
Swin Transformer
Main Idea
- Inductive Bias Reintroduced
- 각각의 쿼리 토큰은 작은 윈도우를 통해 인접한 토큰들을 참조함
- Hierarchical Structure
- 고정된 크기의 패치를 사용하는 것이 아니라 점진적으로 증가 (16x16 → 32x32 → 64x64 ...)
- Shifted Window (Swin) Partitioning
- 첫 번째 아이디어에서의 윈도우가 가까운 다른 패치들도 grouping 할 수 있도록 움직임
- Relative Position Bias
- 세 번째 아이디어를 적용할 경우 positional encoding이 복잡해지기 때문에 relative position bias를 적용하여 보완
Idea 1

- 작은 윈도우를 설정하여 이들끼리만 서로 참조하도록 함
- 그림의 경우 윈도우 안에 있는 4개 패치 중 하나가 쿼리로 선정되면, 이 4개의 패치들만 참조하도록 함
Idea 2

- Patch Merging을 통해 패치 사이즈 P가 2배로 증가함
- 앞선 단계에서 P=4로 self-attention이 수행되었다면
- 그림과 같이 4개의 임베딩을 concatenation (4C 차원)
- FC-layer를 통과시켜 2C 차원으로 줄임과 동시에 통합
- 이제 2C차원의 2P x 2P 크기 패치들로 다시 self-attention 수행
- 이때, 윈도우 크기는 기존과 동일하게 4개의 패치를 담을 수 있도록 함
Idea 3

- 윈도우를 (M/2, M/2) 만큼 이동시켜 겹치지 않았던 패치들까지 포함하여 self-attention 수행
- 가장자리 부분인 masked self-attention 수행
Idea 4

- M 크기의 윈도우 안에서 발생할 수 있는 상대적 위치 차이는 [-M + 1, M - 1]
- 이러한 상대적 위치 차이를 고려한 bias Matirx \( B \)를 추가함
Overall Architecture
Time Complexity Analysis
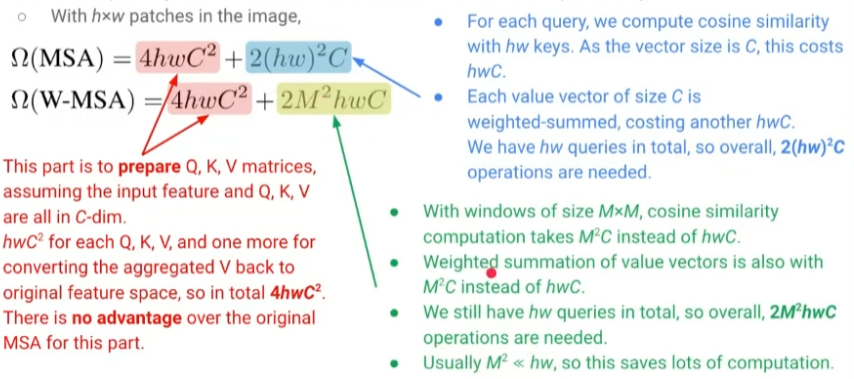
- MSA나 W-MSA나 Q, K, V 행렬을 만드는 시간복잡도는 동일
- 각각에 대해서 \( hwC^2 \)인데 총 4개 필요
- Self-attention의 경우
- MSA
- hw 개의 키와 내적 연산 → \( hwC \) (C는 벡터 크기)
- 가중합 → 마찬가지로 \( hwC \)
- \( 2hwC \)가 hw 개의 쿼리에 대해 이루어지므로 최종적으로 \( 2{(hw)}^2C \)
- W-MSA
- 키, 밸류를 윈도우 내에서만 참조하므로 \( 2M^2C \)
- hw 개의 쿼리에 대해 이루어지므로 최종적으로 \( 2M^2hwC \)
- MSA
- 보통 \( M^2 << hw \)이므로 상당한 비용을 아낄 수 있음
CvT: Convolutional Vision Transformer
Main Idea

- Swin Transformer와 마찬가지로 inductive bias를 다시 도입했으나 컨볼루션 연산을 보다 직접적으로 사용
Convolutional Token Embedding
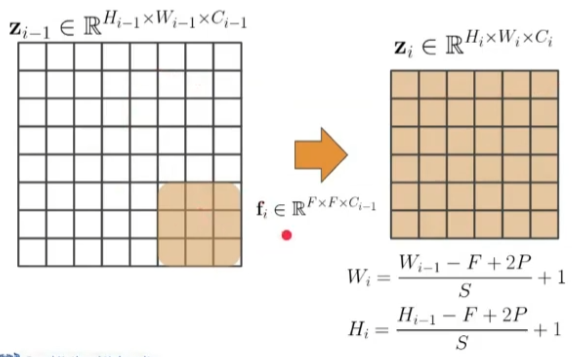
- 피처 맵 크기를 조절하기 위해 conv-layer 적용
- Swin Transformer에서 Patch Merging을 위해 FC-layer를 통과시켰다면, CvT에서는 그냥 conv-layer 적용
- 일반적인 CNN과 비교해보면 conv-layer 사이 사이에 추가적인 self-attention layer가 삽입된 형태로 볼 수 있음
Convolutional Transformer Block

- Q, K, V를 구성할 때 컨볼루션 연산을 사용 (기존의 경우 내적, FC-layer)
- Squeezed convolutional projection
- Key, Value를 참조할 때 stride를 1보다 크게 설정하여 출력 크기를 줄임
Overall Architecture
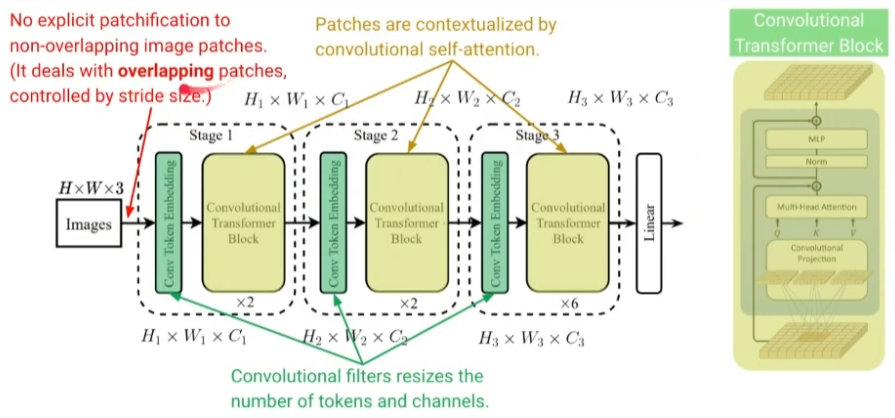

- patchification이 아닌 stride를 조절하여 컨볼루션을 수행하는 방식을 통해 토큰 수와 채널을 resizing 함
Transformer-based Video Models
ViViT: Video Vision Transformer
Model 1

- ViT를 비디오 분류 task에 적용하여 단일 이미지가 아닌 여러 장의 이미지로 단순 확장
- \( n_t \times n_w \times n_h \) 개의 패치 (\( n_h \): # rows, \( n_w \): # columns, \( n_1 \): # frames)
- computational overhead: 거의 \( n^6 \)\
- 이후 Uniform frame sampling(e.g. 프레임의 띄엄띄엄 사용), Tubelet embedding(여러 프레임 통합)과 같은 방식을 적용해서 약간의 성능 개선
Model 2: Factorized Encoder

- 프레임 각각이 ViT와 동일하게 Spatial Transformer Encoder로 들어감
- 각각의 cls 토큰 결과들로 Temporal Transformer Encoder로 다시 들어감
- Complexity: \( O({n_h}^2{n_w}^2 + {n_t}^2) \)
Model 3: Factorized Self-Attention

- Model 1과 동일한 아키텍처인데, transfomer block 안에서 다음의 두 단계를 순차적으로 거침
- Spatial Self-Attention Block: 동일한 temporal index의 토큰 끼리 spatially self-attention 수행
- Temporal Self-Attention Block: 동일한 spatial index의 토큰 끼리 temporally self-attention 수행
- [CLS] 토큰의 사용성이 애매해짐
Model 4: Factorized Dot-Product Attention

- Multi-head attention을 Spatial Head와 Temporal Head로 나눠서 사용
Experiments and Discussion
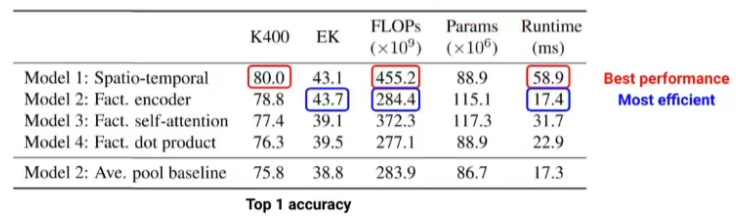
- Model 1이 성능은 가장 좋으나 비용이 매우 높음
- Model 2가 성능-비용 간의 trade-off가 가장 좋음
- ViT가 성능이 잘 나오려면 대규모 데이터셋이 필요한데 비디오 데이터셋은 그러한 게 마땅히 없음
- Model 2에서 Spatial Encoder 부분을 사전 학습된 ViT를 적용할 수 있어서 유용
TimeSFormer
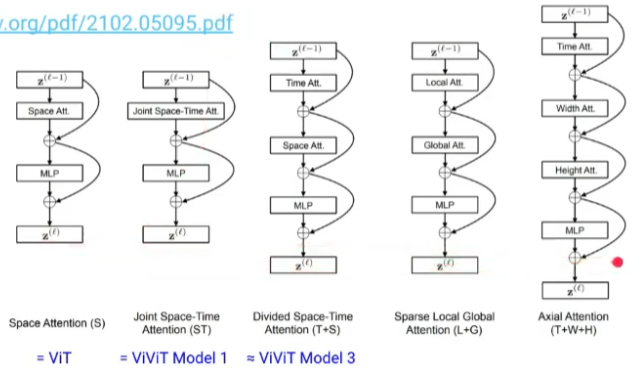

MViT: Multiscale Vision Transformers
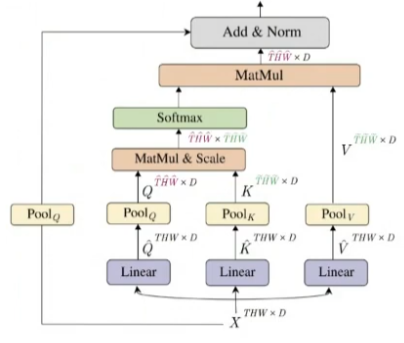
- CvT와 유사한 아이디어를 비디오에 적용
- Multi Head Pooling Attention을 적용하여 Q, K, V의 크기를 줄여줌
Overall Architecture

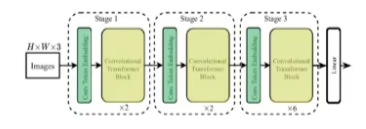
- cube1이 CvT의 Conv Token Embedding layer와 동일
- CvT에서는 conv 연산을 적용했지만 MViT에서는 pooling 연산을 적용한 MHPA를 통해 피처 맵 크기를 줄임
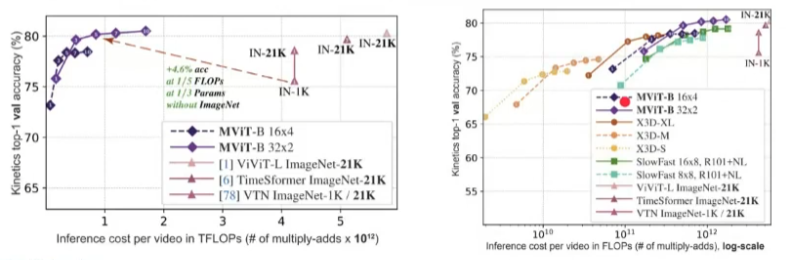
Performance Discussion
'Computer Vision' 카테고리의 다른 글
| [Computer Vision] Metric Learning (0) | 2024.10.01 |
|---|---|
| [Computer Vision] Segmentation (2) | 2024.09.30 |
| [Computer Vision] Object Detection (1) | 2024.09.29 |
| [Computer Vision] Transformers I (0) | 2024.09.25 |
| [Computer Vision] RNN-based Video Models (3) | 2024.09.24 |