본 포스팅은 서울대학교 이준석 교수님의 '시각적 이해를 위한 머신러닝 (2023 spring)' 강의를 바탕으로 작성되었습니다.
모든 내용의 출처는 해당 강의에 있습니다.
Courses: http://viplab.snu.ac.kr/viplab/courses/mlvu_2023_1/index.html
Youtube: https://www.youtube.com/watch?v=-iwEKM56BpU&list=PL0E_1UqNACXDTwuxUzCl5AeEjXBfWxCwc&index=13
RNN-based Spatio-Temporal Modeling
LRCN
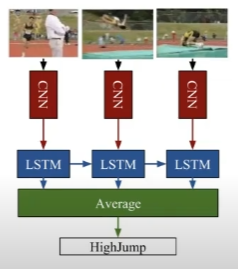
- 비디오는 프레임의 시퀀스이므로, CNN을 통해 일련의 시퀀스로부터 특징을 추출하고 이를 RNN에 넣는 것이 가장 기본적인 RNN-based Video Modeling
- LRCN(Long-term Recurrent Convolutional Network)이 그러한 예시
- 사전 학습된 CaffeNet으로 프레임들의 특징을 추출하고 이를 LSTM에 입력
- 각각의 프레임들에 대한 예측을 averaging하여 종합
Beyond Short Snippets
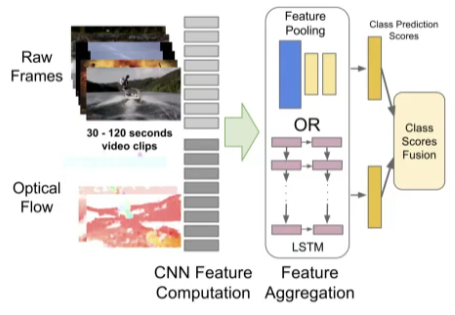
- 2014년 까지의 기존의 비디오 연구는 16프레임 정도로 굉장히 짧은 프레임으로 이루어짐
- 더 길고(최대 5분) 복잡한 내용을 담고 있는 비디오를 다뤄보자는 취지로 시작
- Raw Frame에 대해서는 1fps를 적용 (초당 1프레임, 장면 전환을 이해하는 정도)
- 동작에 대한 정보를 살리고자 Optical Flow를 피처로서 추가적으로 적용 (15fps)
- 이들의 정보를 통합하는 데에 있어 추출된 conv-feature들에 대해 Pooling, LSTM 두 가지 방식을 적용해봄
- Pooling
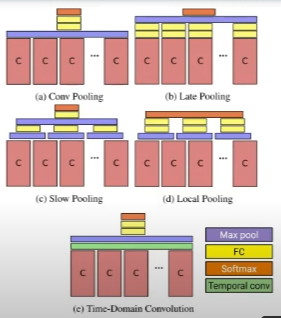
- Conv pooling: 가장 간단한 max pooling. averaging이 아닌 max를 사용한 이유는 비디오 길이가 긴 만큼 핵심 정보를 max로서 살리기 위함
- Late pooling: FC layer를 몇 개 더 쌓고 max pooling
- Slow pooling: FC layer를 사이에 넣은 계층적 구조
- Local pooling
- Time-domain conv: max pooling 이전에 1x1 conv를 적용하여 차원 축소
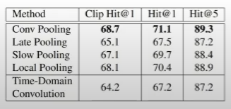
- 결과적으로 Conv pooling이 가장 성능이 좋았음
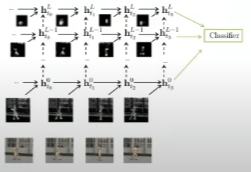
- LSTM
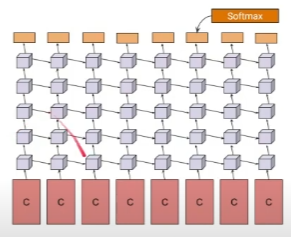
- 그림과 같이 각 프레임으로부터 추출된 conv-feature들에 대해 Multi-layer LSTM을 적용
- 예측을 종합하기 위한 여러 방법을 시도했고 결과적으로 Weighted averaging 방식이 가장 좋았음 (약간의 차이로)
- Pooling vs. LSTM
- LSTM이 조금 더 좋은 성능
- Conv pooling에서 프레임을 4배 정도로 증가시켰을 때는 LSTM과 유사해짐
- 공간적인 정보가 살아있는 conv-feature 대신 CNN의 말단에 있는 FC 레이어를 거친 FC feature를 넣었을 때는 성능이 매우 감소함
FC-LSTM
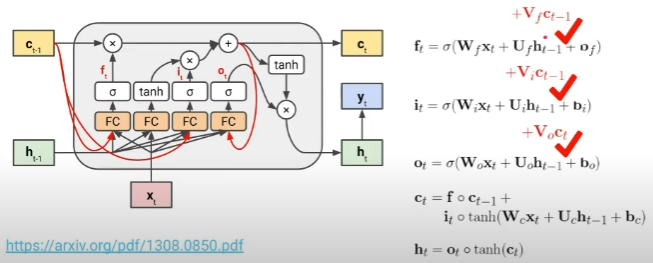
- long-term memory인 cell state도 게이팅에 관여하도록 하고자 하는 아이디어
- 그림과 같이 cell state를 선형변환한 \( Vc_{t-1} \)를 게이트에 추가
- 이와 같은 변화를 채택하여도 여전히 FC를 직접적으로 통과하지 않으므로 그래디언트가 잘 흐름
ConvLSTM
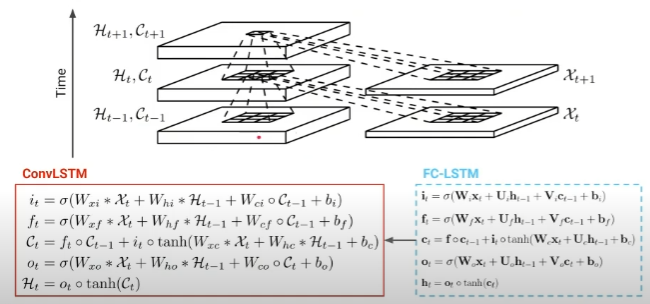
- 앞선 FC-LSTM에 대해 다음과 같이 model spatio-temporal dynamics로의 두 가지 확장
- input (x)와 hidden (h, c)를 벡터에서 행렬로 확장 (배치 단위를 고려하면 실제로는 3D tensor)
- 기존에 FC 형태였던(행렬곱) Weights (W, U)를 컨볼루션 연산으로 대체
- LSTM 셀 안에 있는 i, f, o, c, h가 2D로 변환되며 공간적 정보를 유지하기 위해 모든 연산이 컨볼루션으로 바뀜
- multi-layer LSTM과 같이 여러 시간대로 쌓임
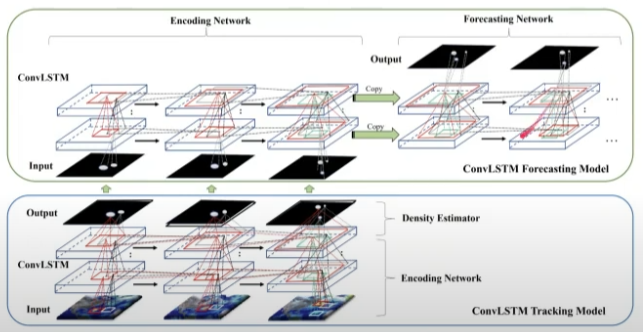
- seq2seq 구조에 적용하여 인코더로부터 추출된 마지막 hidden matrix를 가지고 디코더에서 미래를 예측하는 task를 수행할 수 있음 (e.g. Hurricane Tracking & Forecasting)
ConvGRU
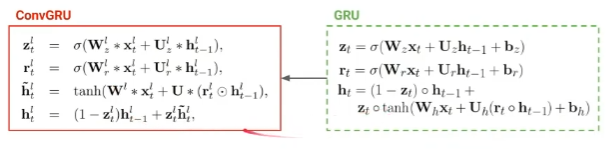
- LSTM 대신 GRU를 적용
- 각 레이어에서 one-step 이전의 hidden state와 한 층 밑의 hidden state 외에도 2D input feature \( x \)를 추가적으로 입력 받음
Attention Mechanism
Information Loss with RNN
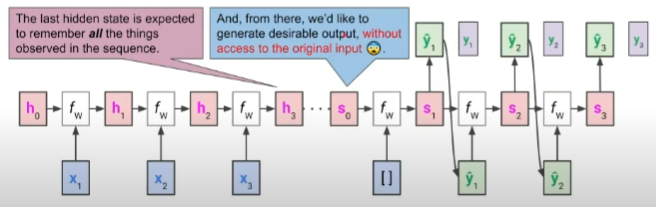
- RNN에서 전체 시퀀스는 그 길이에 상관 없이 하나의 임베딩으로 인코딩됨
- 이 임베딩이 모든 정보를 담고 있기를 원하지만 실제로는 긴 길이의 시퀀스의 경우 정보 손실이 불가피함
- 먼저 입력된 정보들은 더 손실되기 쉬움
- 이를 해결하기 위해 마지막 하나뿐만 아니라 모든 hidden state를 반영하고자 하는 것이 어텐션 아이디어의 기초가 됨
Attention Idea
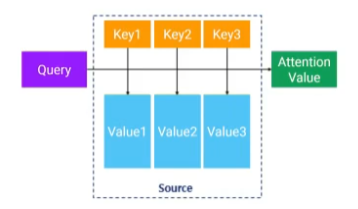
- Attention function: Attention (Q, K, V) = Attention value
- query는 곧 문맥이자 현재의 상황이라면 key-value 쌍은 레퍼런스
- attention value는 value들의 가중합인데, 이 가중합에 대한 가중치가 높다는 것은 query와 (value에 딸려있는) key 간의 상관관계가 높다는 뜻을 의미
- 일반적으로 Q와 K는 차원이 같음
- V와 Attention value는 차원이 같음
- 많은 경우 4개를 모두 같은 차원을 사용
- seq2seq 모델에서의 응용
- Q (Query): t일 때 디코더에서의 hidden state
- K (Keys): 모든 시간에 대해 인코더에서의 hidden states
- V (Values): 모든 시간에 대해 인코더에서의 hidden states
Dot-Product Attention
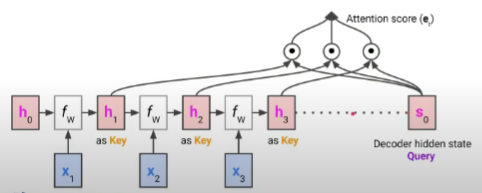
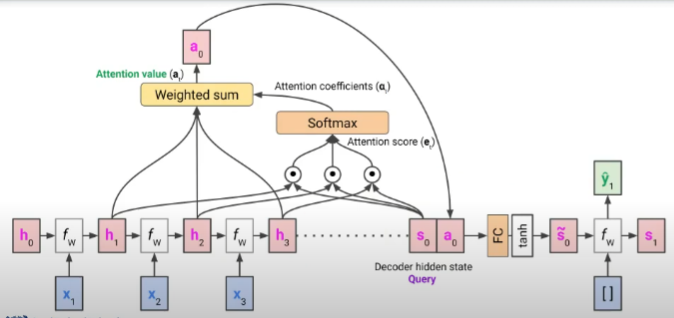
- 그림을 보며 해석해보자면 현재 디코더 hidden state를 Query라고 할 수 있음
- 인코더 hidden state들은 Key, Value 두 역할을 모두 하는데 Key로서는 Query와의 내적을 통해 Attention score를 구하게 됨
- 이 Attention score에 softmax를 취해 Attention coefficients를 구함
- 인코더 hidden state들이 Value로서 사용될 때는 앞서 Attention coefficients와의 가중합을 통해 최종적으로 Attention value를 구하게 됨
- 다른 형태의 어텐션 방법들도 존재하나, dot-product 방식이 파라미터 수도 적고 학습도 쉬워서 많이 사용됨
Attention-based Video Models
MultiLSTM
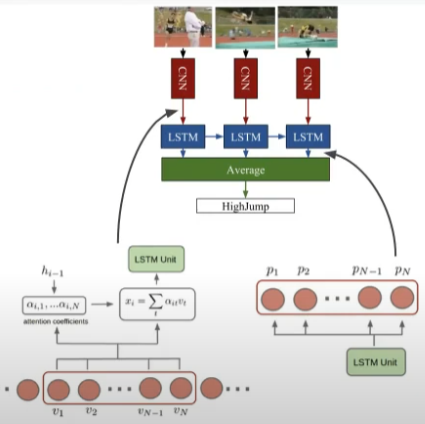
- 기본적으로 LRCN과 유사한 구조
- Multiple input: LSTM에 단일 프레임을 입력받는 대신 N개의 최근 프레임들에 대해 어텐션 적용
- Query: LSTM의 이전 hidden state
- Key, Value: 최근 N개의 입력 프레임 피처
- Attention value: 최근 N개의 프레임 피처에 대한 가중합
- Multiple output: 마찬가지로 최근 N개의 프레임에 대한 예측을 출력
Visual Attention
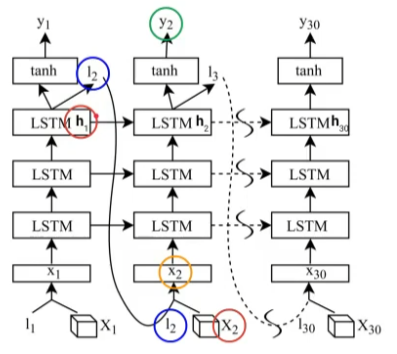
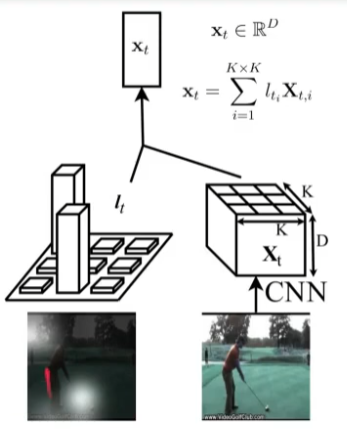
- 그림을 보면서 설명하자면 각 단계마다 다음의 과정을 수행
- LSTM의 마지막 hidden state \( h_1 \)이 Query로 사용됨
- 다음 입력 이미지의 마지막 conv-feature인 \( X_2 \)와 어텐션을 수행하여 spatial attention coefficients \( l_2 \)를 얻음
- \( X_2 \)와 \( l_2 \) 간의 가중합을 계산하여 attention value \( x_2 \)를 얻고 이것이 LSTM의 입력으로 들어감
- 클래스 예측 \( y_2 \)를 수행하고 마찬가지로 이번에는 \( h_2 \)를 Query로 동일하게 반복
- Spatial attention
- 마지막 conv-layer feature인 \( X_t \)는 그림과 같이 K x K x D 차원
- K x K 개의 regional 피처들이 element-wise로 가중합되어 D 차원의 \( x_t \) 출력
- Attention summary
- Query: 마지막 LSTM의 이전 hidden state \( h_{t-1} \)
- Key, Value: input \( X_t \)로부터 K x K 차원의 regional 피처
- Attention value: regional 피처들의 가중합. 가중치는 곧 \( h_{t-1} \)과 얼마나 유사한가를 의미
- 의미: 현재 time step에서 지금까지의 프레임들에 대한 의미를 고려했을 때 새로운 입력에 대해서는 어느 부분에 집중을 해야하는가
'Computer Vision' 카테고리의 다른 글
| [Computer Vision] Metric Learning (0) | 2024.10.01 |
|---|---|
| [Computer Vision] Segmentation (2) | 2024.09.30 |
| [Computer Vision] Object Detection (1) | 2024.09.29 |
| [Computer Vision] Transformers II (4) | 2024.09.27 |
| [Computer Vision] Transformers I (0) | 2024.09.25 |