
더보기
CS231n 강의 홈페이지: https://cs231n.stanford.edu/
CS231n Spring 2017 유튜브 강의 영상: https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk
강의 슬라이드 & 한글 자막: https://github.com/visionNoob/CS231N_17_KOR_SUB
Introduction to Image Classification
- 이미지 분류는 컴퓨터 비전의 핵심 작업 중 하나로, 사전 정의된 카테고리 중 하나의 라벨을 이미지에 올바르게 할당하는 것
- 예를 들어, 입력 이미지로 귀여운 고양이 사진이 주어졌을 때, 시스템은 이 이미지가 고양이, 개, 트럭, 비행기 등의 카테고리 중 어디에 속하는지 결정해야함
- 이는 인간에게는 쉽지만 기계에게는 매우 어려운 작업
Challenges in Image Classification
- Pixel Representation
- 컴퓨터는 이미지를 하나의 객체가 아닌 큰 숫자 집합으로 인식함. 예를 들어, 800x600 이미지의 각 픽셀은 빨강, 초록, 파랑(RGB) 성분을 나타내는 세 개의 숫자로 표현됨
- 이러한 숫자 집합에서 '고양이'를 인식하는 것은 상당히 어려운 작업
- Semantic Gap

Semantic Gap
- '고양이'라는 라벨은 인간이 이미지에 붙인 의미상의 라벨에 불과하며 컴퓨터는 이를 단지 숫자 집합으로만 인식
- 미묘한 이미지 변화에도 픽셀 값은 크게 변하지만, 이는 여전히 고양이이고 이를 판단할 수 있어야 함
- Variations and Roburtness
- 고양이라는 개체 자체의 변형(Deformation), 조명 변화(Illumination), 시점 변화(View point), 가려짐(Occlusion)이나 배경과 유사한 경우(Background Clutter)등과 같은 다양한 상황에서도 고양이를 인식할 수 있어야 함
- 또한 고양이라는 하나의 개념 안에도 다양한 생김새, 크기, 색상, 나이가 존재할 수 있는 Intraclass Variation도 처리할 수 있어야 함


Previous Approaches to Image Classification

- 이미지 입력을 받아 카테고리를 출력하는 Python 메서드를 작성한다고 가정하면, 객체 인식의 경우 숫자 정렬 문제처럼 명확한 단계별 알고리즘이 존재하지 않음
- 이에 대한 이전의 시도들은 Hubel과 Wiesel의 연구를 근거로, 이미지로부터 우선적으로 edges를 계산한 후 다양한 coners와 edges를 각 카테고리로 분류하는 것이었음
- 하지만 이런 방식은 고양이가 아닌 다른 객체를 인식해야 하는 경우 이에 대해서도 별도로 만들어야 하기 때문에 강인하지 못하고 확장성 또한 없음
Data-Driven Approach

- 직접 규칙을 작성하는 대신 Google Image Search와 같은 도구를 이용해 인터넷에서 각 카테고리 별 방대한 데이터를 수집함
- 수집한 데이터를 바탕으로 머신러닝 모델을 학습시키고 학습된 모델은 새로운 이미지로 테스트했을 때도 객체를 잘 인식해낼 것
- 이에 따라 이제는 하나의 함수가 아닌 함수 2개가 필요함
- Train 함수 ▶ 입력은 이미지와 레이블, 출력은 모델
- Predict 함수 ▶ 입력은 모델, 출력은 이미지의 예측값
Nearest Neighbor (NN)
- Basic Concept
- Train ▶ 별다른 연산을 할 필요 없이 모든 학습 데이터를 기억
- Predict ▶ 새로운 이미지가 들어오면, 기존 학습 데이터와 비교하여 가장 유사한 이미지의 레이블로 예측
- Example using the CIFAR-10 Dataset
- Training Dataset: 10 카테고리, 50K 이미지 & Test Dataset: 10K 이미지
- 비교 함수로는 L1 Distance 사용 ▶ Pixel-wise로 두 이미지 간의 차이(절대값)를 구하고 모두 더함

L1 Distance - 우측 그림의 가장 왼쪽 열은 테스트 이미지이고 오른쪽 방향으로는 학습 이미지 중 테스트 이미지와 유사한 순으로 정렬
- 테스트 이미지가 개인 두 번째 행을 봤을 때 가장 가까운 이미지도 개이지만 사슴이나 말 같은 이미지도 보임

- Python Implementation
- NumPy를 사용하여 vectorized 연산 (코드 간결화)
- Train 함수 ▶ 단순히 학습 데이터를 기억

def train(self, X, y): - Test 함수 ▶ 입력 이미지와 모든 학습 데이터를 L1 Distance로 비교하여 예측 레이블을 출력

def predict(self, X):
- Limitations
- Train Time ▶ 상수 시간 복잡도 O(1)
- Test Time ▶ 모든 학습 데이터와 비교해야 하므로 O(N)의 시간 복잡도를 가짐
- 실제 응용에서는 Train Time은 길지라도 Test Time이 짧은 것이 중요한데 NN의 경우 반대임. 따라서 적합하지 않다고 볼 수 있음
- Decision Regions
- NN의 결정 영역(decision regions)을 시각화하면 노이즈나 비정상적인 데이터로 인해 오분류가 발생할 수 있음
- 각 점은 학습 데이터이고 해당 점의 색은 클래스 레이블을 나타냄
- NN은 공간을 나누게 되는데, 우선 2차원 평면 상의 모든 좌표에서 각 좌표가 어떤 학습 데이터와 가장 가까운지 계산한 후, 각 좌표를 해당 클래스로 칠함
- NN은 '가장 가까운 이웃'에만 초점을 두기 때문에 그림 상의 문제가 발생함 (초록색 영역 한 가운데 노란색 영역, 초록색 영역의 파란색 영역 침범 등)

Decision Regions of NN
K-Nearest Neighbors (K-NN)

- 단순하게 가장 가까운 이웃만 찾기보다는 K개의 가까운 이웃을 찾는 방법
- 가장 단순한 방법은 가장 많은 득표수를 얻은 레이블로 예측하는 것이고 거리별 가중치를 고려하는 등의 복잡한 방법도 존재
- K가 증가함에 따라 결정 경계가 부드러워지고 더 나은 결과를 보임
- 흰색 영역은 '대다수'를 결정할 수 없는 지역이고 이는 다양한 추론 방법을 적용하거나 임의 설정 가능
L1 Distance & L2 Distance

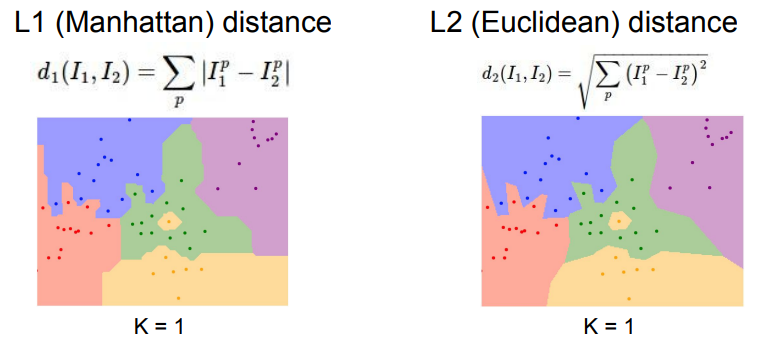
- 어떤 Distance Metric을 사용하는지는 문제 의존적임 (problem-dependent)
- L1 Distance
- 두 이미지의 Pixel-wise 값 차이(절대값)의 합
- 좌표 시스템에 영향을 받음. 즉, 좌표축이 회전하면 사각형이 변하게 됨
- 특징 벡터가 개별적인 의미를 가지고 있는 경우에 유용
- 예를 들어 직원들의 직급을 분류하는 문제에서 봉급이나 연차와 같은 데이터가 존재하는 경우
- L2 Distance
- 편차 제곱합의 제곱근
- 좌표 시스템에 영향을 받지 않음. 좌표축이 회전하더라도 원은 여전히 원
- 특징 벡터가 일반적인 벡터이고 요소들 간의 실질적인 의미를 잘 모르는 경우에 유용
Setting Hyperparameters
- 앞선 경우에서 처럼 가장 좋은 K값, 가장 좋은 Distance Metric 등을 하이퍼 파라미터(Hyperparameters)라고 함
- 최적의 하이퍼 파라미터를 정하는 일은 문제 의존적(problem-dependent)이며 가장 간단한 방법은 데이터에 맞게 다양한 값을 시도해 보고 가장 좋은 값을 찾는 것
- Idea #1 ▶ 훈련 데이터셋(Training Dataset)에 대한 정확도와 성능을 최대화하는 하이퍼 파라미터를 선택

- 절대 해서는 안 되는 방법
- 에를 들어 앞선 NN의 경우 K = 1일 때 훈련 데이터를 완벽하게 분류함
- K의 값이 커질 때 몇 개의 훈련 데이터를 오분류할 수는 있지만 새로운 데이터에 대해서는 더 좋은 성능을 보임
- 딥러닝에서는 궁극적으로 훈련 데이터보다는 한 번도 경험해보지 못한 데이터를 잘 예측하는 일반화 성능이 중요
- Idea #2 ▶ 테스트 데이터셋(Test Dataset)에 대한 정확도와 성능을 최대화하는 하이퍼 파라미터를 선택

- 전체 데이터셋 중 일부를 테스트 데이터셋으로 할당하여 훈련용과 테스트용으로 나눔
- 마찬가지로 테스트 데이터셋에 초점을 맞추더라도, 테스트 데이터셋이 한 번도 경험해보지 못한 새로운 데이터에서의 성능을 대표한다는 보장이 없음
- Idea #3 ▶ 검증 데이터셋(Validation Dataset)을 이용

- 그림과 같이 대부분의 데이터셋을 훈련용으로, 나머지를 검증용, 테스트용으로 나눔
- 하이퍼 파리미터 값을 다양하게 바꿔 가며 '훈련 데이터셋'으로 모델을 학습
- 검증 데이터셋으로 모델을 평가하여 가장 성능이 좋았던 하이퍼 파라미터를 선택
- 개발, 디버깅 등 모든 과정을 마친 후 테스트 데이터셋으로 최종 평가 (이 수치가 논문과 보고서 등에 삽입됨)
- Idea #4 ▶ 교차 검증 (K-fold Cross-Validation)

- 데이터가 부족한 경우에 사용되는 방법
- 테스트 데이터셋을 따로 빼두고 나머지를 그림과 같이 여러 개의 fold로 나눔
- 나눠진 fold가 번갈아 가며 검증 데이터셋의 역할을 수행
- 큰 모델을 학습시키는 딥러닝의 경우 계산량이 많아서 잘 사용되지는 않음
- K값에 따른 성능의 평균과 분산까지 파악 가능

Cross-validation on K
Limitations of K-NN
다음과 같은 이유들로 K-NN은 이미지 분류에 있어서 사용되지 않음
- 매우 느린 속도
- 앞서 언급한 것처럼 K-NN은 test time에서 느린 속도
- 부적절한 Distance Metric

- L1 / L2 Distance는 이미지들 간의 perceptual similarity를 측정하는 척도로는 부적절함
- 그림처럼 우측 세 장의 이미지는 좌측 이미지와 동일한 L2 Distance
- 차원의 저주 (Curse of Dimensionality)

Curse of Dimensionality
- K-NN은 manifold를 가정하지 않기 때문에 공간을 잘 분할하기 위해서는 전체 공간을 밀도 있게 채울 충분한 양의 데이터가 필요함
- 그러나 이는 그림과 같이 차원이 증가함에 따라 필요한 데이터의 수는 기하급수적으로 증가하기 때문에 현실적으로 어려움
Parametric Approach: Linear Clasifier
앞선 K-NN와 달리 선형 분류기(Linear Classifer)는 parametric model


- x
- 입력 이미지. CIFAR-10을 기준으로 32x32x3 → 3072x1
- W
- Weights. 학습되는 파라미터. 가중치라고도 함
- 학습되는 동안 훈련 데이터셋의 정보가 W에 반영됨
- f
- 설계된 함수. 가장 단순한 설계 방법은 그림에서와 같이 W와 x를 곱해주는 것
- 1차원으로 펼쳐진 이미지의 열벡터와 가중치의 내적
- 이미지가 여러 개라면 행렬곱
- 10x1 차원의 f(W, x) = Wx + b가 각 클래스에 대한 예측 스코어가 됨
- b
- Bias. 마찬가지로 학습되는 파라미터
- 특정 클래스에 해당하는 데이터가 유독 많은 것처럼 데이터가 불균형한 경우, 해당 클래스에 상응하는 바이어스가 커지게 됨
Interpreting a Linear Classifier
- Template Matching

- CIFAR-10 데이터셋의 각 클래스에 해당하는 가중치 행 벡터 시각화
- 비행기 클래스의 템플릿을 예로 들면 주로 파란색이고 중앙에 물체가 있는 것을 인식
- 말 클래스의 경우 머리가 두 개인 모습도 보임
- 한계점
- 각 클래스에 대해 단 하나의 템플릿만 학습
- 클래스에 다양한 특징이 있더라도 하나의 템플릿으로 평균화하여 학습
- 예: 머리 두 개의 말 템플릿
- 고차원 공간에서의 Linear Classification

- 이미지를 고차원 공간의 한 점으로 보는 관점
- Linear classifier는 선형 결정 경계를 학습하여 각 클래스를 구분
- 한계점

- Parity Problem
- 0보다 큰 픽셀 값이 홀수 개/짝수 개인지를 분류, 영상 내 동물이나 사람의 수가 홀수/짝수인지 등
- Linear classifier로는 한 선으로 분류 불가
- Multimodal Problem
- 그림 가장 우측과 같이 한 클래스가 여러 구역에 분포하는 경우
- 예: 말의 왼쪽 머리와 오른쪽 머리가 각각 다른 구역
- Parity Problem
'CS231n' 카테고리의 다른 글
| [CS231n] Lecture 7 | Training Neural Networks II (0) | 2024.08.13 |
|---|---|
| [CS231n] Lecture 6 | Training Neural Networks I (0) | 2024.08.08 |
| [CS231n] Lecture 5 | Convolutional Neural Networks (0) | 2024.07.30 |
| [CS231n] Lecture 4 | Introduction to Neural Networks (0) | 2024.07.29 |
| [CS231n] Lecture 3 | Loss Functions and Optimization (0) | 2024.07.26 |